|
Một tựa đề đầy hứa hẹn (“ADN không biết nói dối”) và một tiêu đề đầy tính khẳng định (“Xác định quan hệ huyết thống: đạt chính xác 99,9%”) (1) có lẽ đem lại sự tin cậy tuyệt đối của bạn đọc đối với kĩ thuật phân tích DNA trong việc nhận dạng kẻ tội phạm hay xác định một mối quan hệ huyết thống. Tuy nhiên, trong thực tế, kĩ thuật phân tích DNA – cũng như bất cứ kĩ thuật sinh học nào – cũng có sai sót, và trong một số trường hợp, sự sai sót dẫn đến thảm họa khó lường cho đương sự. Trong bài viết ngắn này, tôi sẽ phân tích tại sao có sai sót trong phân tích DNA và cách diễn dịch kết quả DNA sao cho dễ hiểu hơn. Từ khi kĩ thuật phân tích DNA được phát triển vào giữa thập niên 1980, xét nghiệm DNA đã được sử dụng rộng rãi trong việc chẩn đoán lâm sàng, nghiên cứu y sinh học. Ngoài lĩnh vực ứng dụng “truyền thống” này, trong khoảng trên dưới 10 năm gần đây, xét nghiệm DNA còn được ứng dụng trong việc xác định mối liên hệ huyết thống và pháp y. Ở Mĩ từ năm 1986 kết quả xét nghiệm DNA đã được chấp nhận là một bằng chứng trước tòa. Sau đó, các tòa án trên thế giới cũng theo bước và chấp nhận xem xét kết quả xét nghiệm DNA trong quá trình xét xử. Xét nghiệm DNA đã giúp cho các cơ quan thi hành luật pháp truy tìm tội phạm một cách hữu hiệu, và giúp tòa án giải oan cho những trường hợp bị kết tội sai lầm. Ít ai biết rằng chính do xét nghiệm DNA (qua nước bọt trên tem thư) đã giúp cho cơ quan điều tra liên bang Mĩ phát hiện nhân vật “Unabomber”, tức Tiến sĩ toán học Theodore Kaczynski, người từng gây kinh hoàng cho xã hội Mĩ một thời gian vì ông gửi bom thư (thư có chất nổ) đến các nhân vật lãnh đạo thuộc các công ti kĩ nghệ mà ông không ưa thích. Cũng chính qua so sánh DNA từ một bộ xương khai quật từ Brazil và vài người thân trong gia đình mà các nhà sử học đã xác định được hài cốt đó là của Josef Mengele, một nhân vật tội phạm chiến tranh khét tiếng thời Nazi ở Đức.
Những thành công ngoạn mục về ứng dụng xét nghiệm DNA trong pháp luật trong một thập niên gần đây đã làm nên một cuộc “cách mạng” pháp đình. Có thể nói không ngoa rằng phân tích DNA là một phát triển quan trọng nhất trong lịch sử pháp y trong thời đại chúng ta, thậm chí trong lịch sử con người. Trong thời gian qua, kết quả xét nghiệm DNA được giới báo chí, luật sư, thậm chí quan tòa ca ngợi là bằng chứng chính xác nhất, khách quan nhất so với các loại bằng chứng như lời khai của nhân chứng (có độ tin cậy thấp nhất) và di chứng từ hiện trường. Trong việc thẩm định quan hệ huyết thống, kết quả DNA cũng thường được xem là một phán quyết sau cùng, và đã gây ra vô số thảm cảnh cho gia đình. Niềm tin tuyệt đối vào kết quả xét nghiệm DNA được khẳng định vì các nhà khoa học liên quan thường phát biểu trước tòa án và báo chí đại chúng bằng những ngôn từ khẳng định như “theo kinh nghiệm 30 năm của tôi, kết quả DNA chính xác 100%”, hay “tôi xác định đây là DNA của bị can”, v.v... Tuy nhiên, trong thực tế, xét nghiệm DNA, cũng như bất cứ phân tích khoa học nào, đều có phần bất định, không chắc chắn. Không bao giờ có chuyện chính xác 100%. Mà câu nói “chính xác 100%” có nghĩa gì thì cũng chẳng ai giải thích tường tận. Thật ra, có khi chính người phát biểu câu đó cũng chỉ lặp lại từ người khác, chứ không biết mình nói gì! Không phải bất cứ bằng chứng DNA nào cũng được xem là kết quả cuối cùng và bằng chứng duy nhất để kết tội một người nào đó, hay để kết luận mối quan hệ huyết thống.
Sai lầm từ bằng chứng DNA
Trường hợp của Brandon Mayfield không phải là một trường hợp hiếm hoi hay cá biệt. Trong một phân tích 86 trường hợp bị hàm oan ở Mĩ, các nhà nghiên cứu phát hiện có 54 trường hợp (tức 63%) là do sai lầm từ xét nghiệm DNA (3). Tại sao có sai sót trong xét nghiệm DNA? Để hiểu tại sao có sai sót và tình trạng bất định trong việc diễn dịch kết quả xét nghiệm DNA, cần phải xem xét qua qui trình ứng dụng bằng chứng DNA vào pháp đình.
Mỗi bước và mỗi chuỗi liên hệ giữa hai bước trong qui trình trên đều có thể sai sót. Nếu sai sót xảy ra từ bước thứ nhất thì tất cả các kết quả và thông tin hai bước sau trở thành vô nghĩa, và bằng chứng không được chấp nhận trước tòa.
Trong bước một, kết quả xét nghiệm DNA có thể phạm sai sót về kĩ thuật như thất bại của enzim, hoặc mẫu (mẫu máu, tóc, nước bọt …) bị nhiễm hay hư hỏng, hoặc nồng độ muối [dùng cho phân tích DNA] bất bình thường, hoặc do lẫn lộn mẫu máu, hoặc đơn giản do sai sót của kĩ thuật viên. Rất khó biết tỉ lệ sai sót trong bước một là bao nhiêu (vì ít ai chịu công bố sai sót kĩ thuật!), nhưng kinh nghiệm của người viết bài này thì tỉ lệ sai sót có thể dao động từ 1 đến 5%. Qua tái thẩm định 75 báo cáo trùng hợp hồ sơ DNA, người ta phát hiện 3 sai sót trong bước 1, tức tỉ lệ 4% (4).
Sai lầm từ diễn dịch xác suấtNếu bước một không có sai sót, và nhà chức trách phát hiện một sự trùng hợp, vấn đề đặt ra là xác suất trùng hợp này là bao nhiêu? Để trả lời câu hỏi này, nhà chức trách phải áp dụng lí thuyết xác suất để ước tính xác suất trùng hợp ngẫu nhiên (random match probability – RMP). Để hiểu ý nghĩa xác suất này, cần phải xét qua một trường hợp như sau. Giả sử chuyên gia phân tích DNA lập hồ sơ DNA bằng cách phân tích 6 gen (mỗi gen có nhiều biến thể, tức genotype), và kết quả như sau:
Kết quả xét nghiệm trên cho thấy biến thể từ 6 gen phân tích từ mẫu lấy từ hiện trường và mẫu lấy từ máu của người bị tình nghi hoàn toàn giống nhau. Nhưng có thể kết luận rằng người bị tình nghi là người bỏ lại mẫu máu tại hiện trường hay không? Câu trả lời là “không”, bởi vì:
(a) có thể có nhiều người khác cũng có biến thể gen giống như người bị tình nghi;
(b) hồ sơ DNA chỉ mới phân tích trên 6 gen, mà trong cơ thể con người có hơn ba mươi ngàn gen (không ai biết con người có bao nhiêu gen). Rất dễ thấy là tăng số gen để thiết lập hồ sơ DNA cũng làm tăng độ tin cậy của phán xét.
Giả dụ trong một quần thể người da trắng (vì tần số gen rất khác nhau giữa các sắc dân), có 21,3% người mang biến thể BB thuộc gen GYPA, 0,5% người mang biến thể AC thuộc gen HBGG, v.v… như bảng thống kê sau đây:
Các tần số này được ước tính từ nghiên cứu trên một quần thể lớn. Từ bảng trên, có thể ước tính xác suất mà một người có hồ sơ DNA như trên là: 0,213 x 0,005 x 0,191 x 0,208 x 0,040 x 0,070 = 0,0000001185, hay 1 trên 8.441.034. Cách tính này dĩ nhiên là dựa vào giả định phân phối của các biến thể trong 6 gen là hoàn toàn độc lập. (Thật ra, phương pháp tính xác suất này là một đề tài vẫn còn tranh cãi trong giới thống kê và toán học, cách tính mà tôi vừa trình bày là rất đơn giản). Đây chính là xác suất trùng hợp ngẫu nhiên, mà luật sư và tòa án sử dụng để làm bằng chứng cho phán quyết. Ý nghĩa thật của xác suất trùng hợp ngẫu nhiên 1 trên 8.441.034 là như sau: nếu người bị tình nghi vô tội (không phải “chủ nhân” mẫu DNA tại hiện trường) thì trong một quần thể xác suất một người có hồ sơ DNA trùng hợp với DNA tại hiện trường là 0,0000001185. Nói theo ngôn ngữ xác suất, đây chính là P (trùng hợp | vô tội). Xin nhấn mạnh, xác suất này không có nghĩa là P (vô tội | trùng hợp). Thế nhưng tiếc thay, rất nhiều người hiểu sai như thế. Và cũng chính vì hiểu sai, mà trong nhiều trường hợp, chỉ vì một con số này, và chỉ xác suất này, mà bao nhiêu người đã vào tù ra khám! Hãy xem qua một phát biểu sau cùng (trước khi bồi thẩm đoàn họp và quyết định) của công tố viên và luật sư bào chữa trong một phiên tòa ở London như sau (5):
Công tố viên: “Hồ sơ DNA tìm thấy từ hiện trường và bị can cực kì hiếm, chỉ xảy ra với tần số 1 trên 10 triệu người. Đây là một xác suất cực kì thấp, và chúng ta phải kết luận rằng với một xác suất như thế, bị can là người có tội. Quí vị bồi thẩm đoàn không còn lựa chọn nào khác, mà chỉ phải kết luận bị can chính là thủ phạm.”
Luật sư cho bị can: “Trong một quần thể 30 triệu người, bất cứ ai cũng có thể là thủ phạm. Một trong những người này thực sự là kẻ phạm tội. Số còn lại vô tội, và mỗi người có xác suất 1/10 triệu mà hồ sơ DNA sẽ trùng hợp với hồ sơ DNA tại hiện trường. Thành ra, có 3 người vô tội nhưng có hồ sơ DNA giống như hồ sơ DNA lấy từ hiện trường. Chúng ta biết rằng bị can có DNA trùng hợp, nhưng ông ta có thể bất cứ ai trong 3 người vô tội kia. Do đó, xác suất mà ông ta có tội là 1/4. Xác suất này không thể xem là ‘ngoài vòng nghi vấn’ được. Quí vị bồi thẩm đoàn không còn lựa chọn nào khác hơn là kết luận rằng khách hàng của tôi vô tội!”
Ở đây, lí giải của công tố viên rất sai lầm! Và sai lầm này cũng rất phổ biến trong luật pháp mà giới logic học đặt tên là “prosecutor fallacy” (ngụy biện công tố viên). Công tố viên (nhầm lẫn) cho rằng xác suất trùng hợp ngẫu nhiên là xác suất mà bị can vô tội. Lí giải của luật sư biện hộ thì khá dài dòng, khó theo dõi, và không hợp lí. Xác suất trùng hợp ngẫu nhiên 1 trên 10.000.000 có nghĩa là: nếu bị can vô tội (tức không phải là “thân chủ” của mẫu DNA lấy từ hiện tường), thì xác suất mà một người được chọn ngẫu nhiên từ một quần thể dân số có hồ sơ DNA giống như hồ sơ DNA từ hiện trường là 1 trên 10 triệu người. Điều quan trọng cần nhấn mạnh là: xác suất trùng hợp ngẫu nhiên không có nghĩa là xác suất bị can vô tội là 0,0000001 (1 trên 10 triệu), và cũng không có nghĩa là xác suất mà bị can có tội là 0,9999999. Ấy thế mà đại đa số bồi thẩm đoàn đều nghĩ và diễn dịch như thế (6)!
Ước tính xác suất phạm tộiQuay lại trường hợp trên, có thể lí giải một cách đơn giản rằng trong một quần thể 30 triệu, có một người thật sự có tội, và số còn lại 29.999.999 người vô tội. Giả định rằng nếu bị can có tội thì kết quả xét nghiệm DNA sẽ cho kết quả dương tính (trùng hợp với DNA lấy từ hiện trường), tức P(T+ | K+) = 1. Trong số 29.999.999 người vô tội, vì P(K+ | T-) = 1/10.000.000, nên sẽ có 3 người có kết quả DNA dương tính. Như vậy, chúng ta kì vọng sẽ có 4 kết quả DNA dương tính, nhưng trong số này chỉ có 1 người là thật sự có tội, cho nên xác suất bị can có tội nếu kết quả DNA dương tính là: 1/4 = 0,25. Có thể theo dõi cách lí giải trên qua biểu đồ sau đây:
Tuy nhiên, cách tính trên tùy thuộc rất lớn vào xác suất ban đầu mà công tố viên (hay luật sự biện hộ) cho rằng bị can có tội. Trong ví dụ trên, xác suất này là 1 trên 30 triệu, và ước số này dựa vào giả định rằng bất cứ ai trong cộng đồng 30 triệu người đều có xác suất mang tội như nhau. Rõ ràng, giả thiết này chỉ có thể chấp nhận được nếu không có bất cứ bằng chứng nào khác để xem xét; nhưng nếu các bằng chứng ngoài DNA có sẵn thì một xác suất như thế không có tính thuyết phục cao. Cách tính vừa diễn giải trên có thể tóm gọn bằng công thức Bayes (7).
Nói tóm lại, việc ứng dụng phân tích DNA trong luật
pháp là một phát triển rất quan
Chú thích và tài liệu tham khảo 1. Xem “AND không biết nói dối” tại http://vietnamnet.vn/psks/2006/04/564154 2. Study of faulty fingerprints debunks forensic science ‘Zero Error’ claim. Website: http://www.sciencedaily.com/releases/2005/09/050913124509.htm 3. Saks MJ, Koehler JJ. The paradigm shift in forensic identification science. Science 5/8/2005, 309:892-895. 4. Koehler JJ. Error and exaggeration in the presentation of DNA evidence at trial. Jurimetrics 1993; 34: 5. Dawid AP. Bayes’ theorem and weighing evidence by juries. Tài liệu có thể tải tại website sau đây: http://www.ucl.ac.uk/~ucak06d/evidence/1day/ba.pdf. 6. Redmayne M. Appeals to reason. The Modern Law Review 2002;65:19-35. 7. Để đơn giản vấn đề và tiết kiệm từ ngữ, gọi K+ là sự trùng hợp giữa mẫu DNA từ bị can và DNA từ hiện trường; K- là kết quả không trùng hợp. Gọi T+ là trường hợp bị can chính là “chủ nhân” của mẫu DNA từ hiện trường, và T- là trường hợp bị can không phải là can phạm. Nói theo ngôn ngữ xác suất thì xác suất trùng hợp ngẫu nhiên có thể viết bằng công thức: P(K+ | T-), tức là một xác suất điều kiện (dấu hiệu “|” là viết tắt từ cụm từ “với điều kiện”). Dĩ nhiên, P(K+ | T-) hoàn toàn khác với P(T+ | K+), tức xác suất bị can là thủ phạm nếu sự trùng hợp xảy ra. P(T+ | K+) chính là xác suất mà chúng ta và bồi thẩm đoàn cần biết. Theo định nghĩa xác suất có điều kiện, xác suất mà bị can có tội nếu kết quả DNA của bị can trùng hợp với DNA tại hiện trường là:
Trong đó, P(T+) là xác suất mà bị can có tội dự vào các bằng chứng khác, và là xác suất mà bị can không có tội. Dựa vào công thức này, có thể lí giải trường hợp trên như sau: giả dụ như ngoài bằng chứng DNA, công tố viên không có bằng chứng nào khác, thì xác suất mà bị can có tội là P(T+) = 1/30.000.000. Chúng ta biết P(K+ | T-) = 1/10.000.000, và giả định rằng nếu bị can có tội thì xác suất mà DNA của bị can trùng hợp với DNA tại hiện trường là 1 (tức P(K+ | T+) = 1). Với các ước số đó, xác suất mà bị can có tội nếu kết quả DNA trùng hợp là:
|
||||||||||||||||||||||||||||||||||||||||||||||||


 Thật vậy, bên cạnh những thành công ngoạn mục đó,
xét nghiệm DNA đã góp phần gây nên những phán quyết
sai lầm nghiêm trọng. Năm 2004, Brandon Mayfield,
một luật sư hành nghề tại thành phố Portland (Mĩ),
bị cảnh sát liên bang Mĩ bắt giam 2 tuần vì bị tình
nghi là thủ phạm đánh bom trên xe
Thật vậy, bên cạnh những thành công ngoạn mục đó,
xét nghiệm DNA đã góp phần gây nên những phán quyết
sai lầm nghiêm trọng. Năm 2004, Brandon Mayfield,
một luật sư hành nghề tại thành phố Portland (Mĩ),
bị cảnh sát liên bang Mĩ bắt giam 2 tuần vì bị tình
nghi là thủ phạm đánh bom trên xe 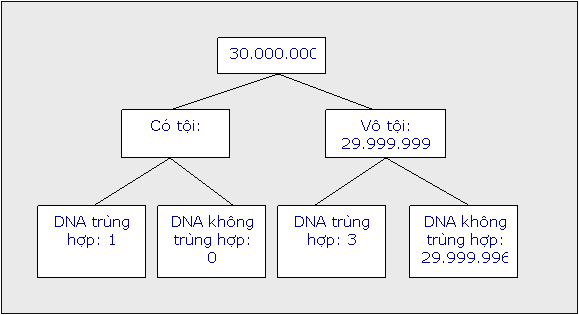
 trọng trong việc
giải quyết vấn đề nhận dạng tội phạm và xác định
quan hệ huyết thống, nhưng không nên xem kết quả xét
nghiệm DNA là một kết quả sau cùng để dựa vào đó mà
quyết định. Trong thực tế, như trình bày trên kết
quả xét nghiệm DNA có thể sai sót từ khâu kĩ thuật.
Tuy mức độ sai sót rất thấp, nhưng nó vẫn là một
nguy cơ có thể gây nên những thảm nạn cho nạn nhân.
Ngay cả khi kết quả xét nghiệm DNA hoàn toàn chính
xác, việc diễn dịch kết quả DNA cũng có thể sai vì
người diễn dịch không hiểu kết quả trùng hợp DNA có
nghĩa gì. Những xác suất trùng hợp DNA như 1 trên
10 triệu, hay thậm chí 1 trên 57 tỉ (như trường hợp
của O. J. Simpson) không có nghĩa là xác suất bị can
vô tội. Kết quả xét nghiệm DNA chỉ có thể xem là
một nguồn bằng chứng trong nhiều bằng chứng khác, và
cần phải được diễn dịch đúng với ý nghĩa mang tính
bất định của nó. Diễn dịch đúng một kết quả xét
nghiệm DNA như trình bày trên đòi hỏi một kiến thức
vững vàng về lí thuyết xác suất và di truyền dân số
học.
trọng trong việc
giải quyết vấn đề nhận dạng tội phạm và xác định
quan hệ huyết thống, nhưng không nên xem kết quả xét
nghiệm DNA là một kết quả sau cùng để dựa vào đó mà
quyết định. Trong thực tế, như trình bày trên kết
quả xét nghiệm DNA có thể sai sót từ khâu kĩ thuật.
Tuy mức độ sai sót rất thấp, nhưng nó vẫn là một
nguy cơ có thể gây nên những thảm nạn cho nạn nhân.
Ngay cả khi kết quả xét nghiệm DNA hoàn toàn chính
xác, việc diễn dịch kết quả DNA cũng có thể sai vì
người diễn dịch không hiểu kết quả trùng hợp DNA có
nghĩa gì. Những xác suất trùng hợp DNA như 1 trên
10 triệu, hay thậm chí 1 trên 57 tỉ (như trường hợp
của O. J. Simpson) không có nghĩa là xác suất bị can
vô tội. Kết quả xét nghiệm DNA chỉ có thể xem là
một nguồn bằng chứng trong nhiều bằng chứng khác, và
cần phải được diễn dịch đúng với ý nghĩa mang tính
bất định của nó. Diễn dịch đúng một kết quả xét
nghiệm DNA như trình bày trên đòi hỏi một kiến thức
vững vàng về lí thuyết xác suất và di truyền dân số
học. © http://vietsciences.org và http://vietsciences.free.fr Nguyễn Văn Tuấn